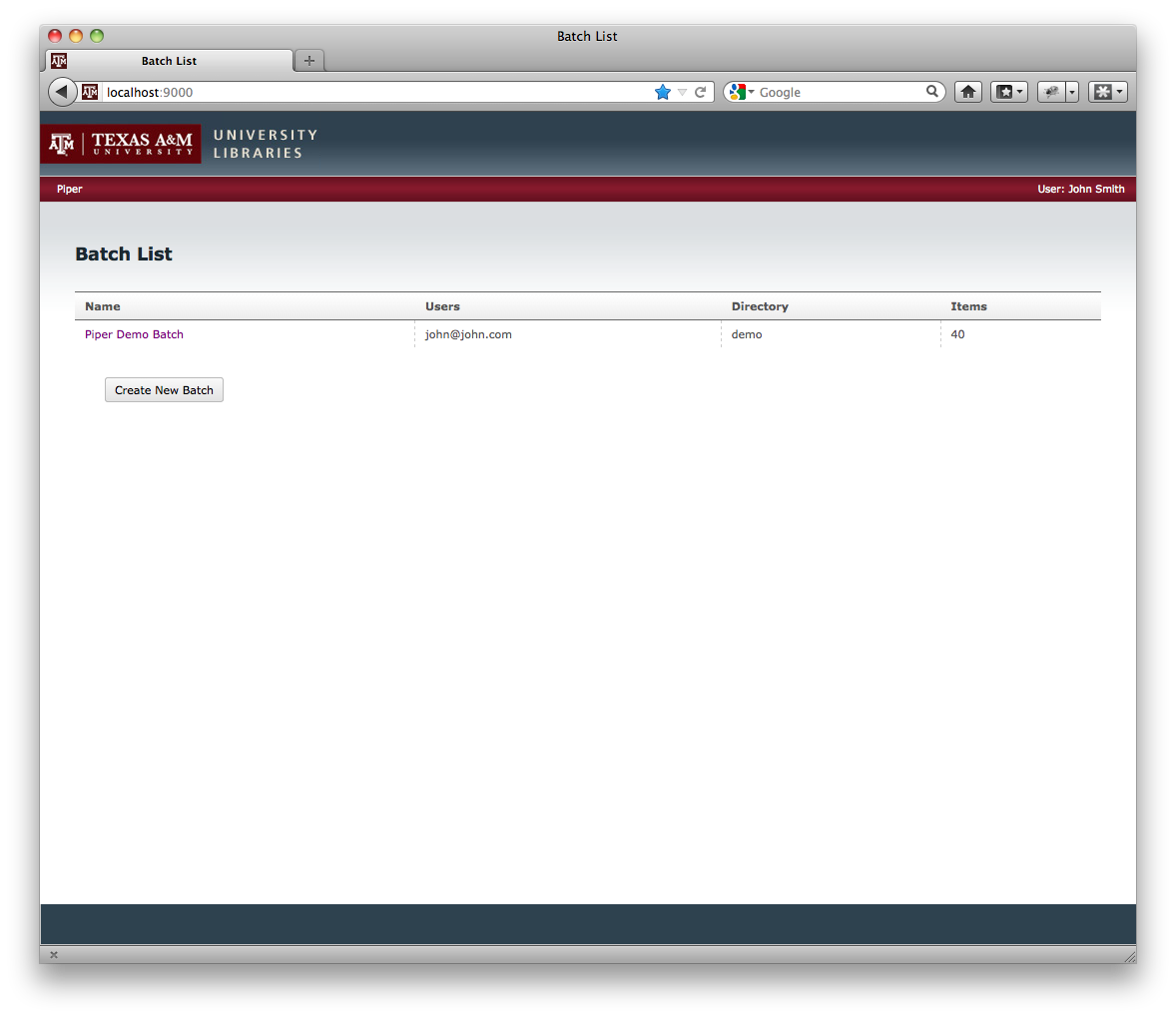
Introducing Piper
Piper is an internal project we have been working on at Texas A&M University Libraries. The project is just in its initial stages at this point with the first kernel of an idea. I expect to that we will expand its capabilities in the future. Piper is basically a repository batch import tool right now, and in the future it could grow into becoming an internal repository workflow tool.
How does Piper fit into the repository ecosystem? It is a behind the scene tool for repository administrators to curate collections. For our initial phase we focused on the sole task of ingesting content into DSpace simple. However, in the future, it may bring in workflow capabilities to ensure quality control, integration with other workflow tools like Vireo, and of course additional repository support.
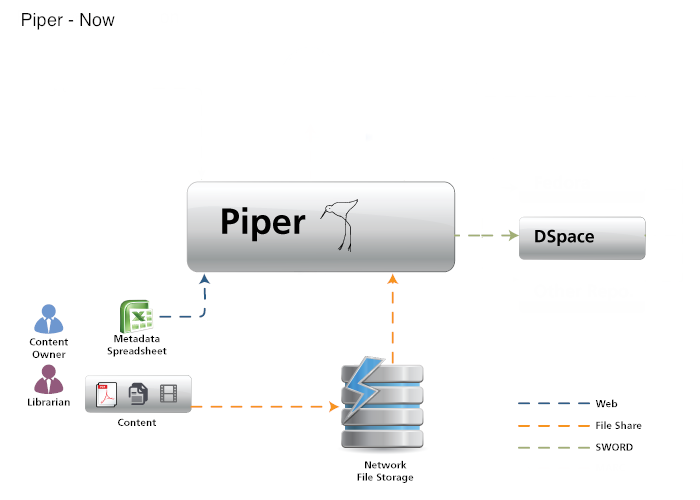
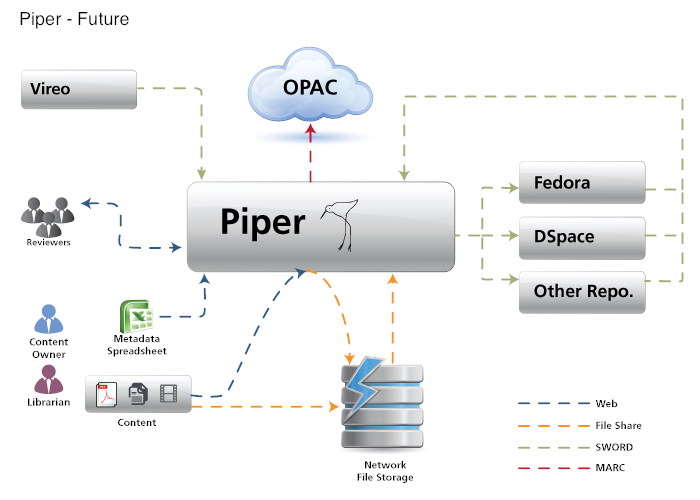
Two figures depicting how Piper fits into the repository ecosystem right now, and ways it could possibly fit in in the future.
How does Piper work?
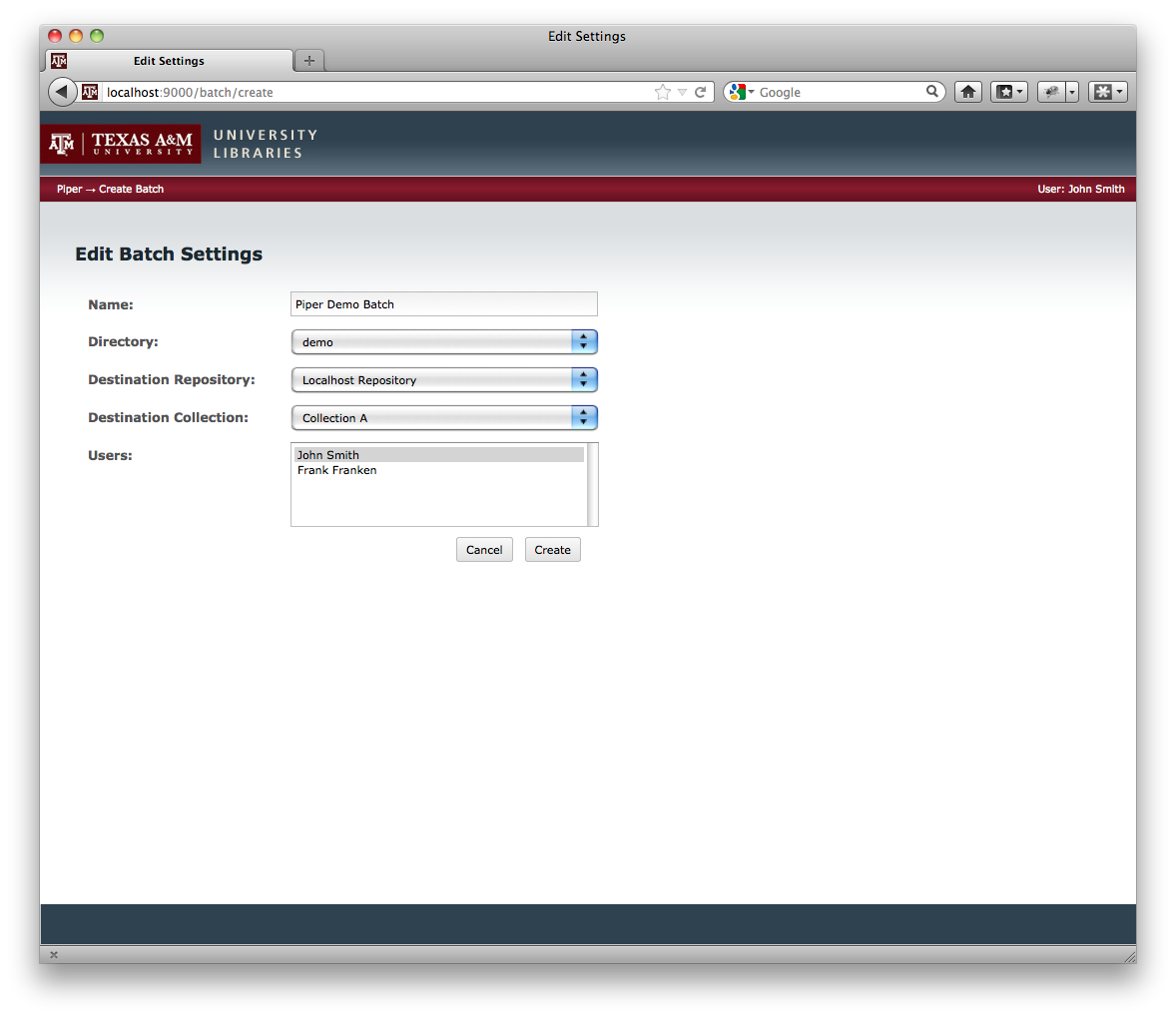
First a content owner works with a librarian to gather their content together. The metadata is captured on a spreadsheet, and all the files are collected into a folder. The folder is copied to shared network storage that both the librarian has access to on their desktop and the server running Piper can access. We chose network file sharing because batches can be bigger than the 4GB limit that the HTTP protocol imposes. In the future, a direct upload mechanism for small batches may be added primarily for convenience. Next, the librarian logs into Piper through their web browser and uploads the spreadsheet with the metadata for the batch. Currently, the only metadata format supported is a Dublin Core spreadsheet where the first column is a reference to the file, and all other columns are a Dublin Core field specified in dot notation. Piper is designed to be easily extensible so each “Ingester” is a simple Spring bean. When uploading a new spread sheet the user selects what format to use.
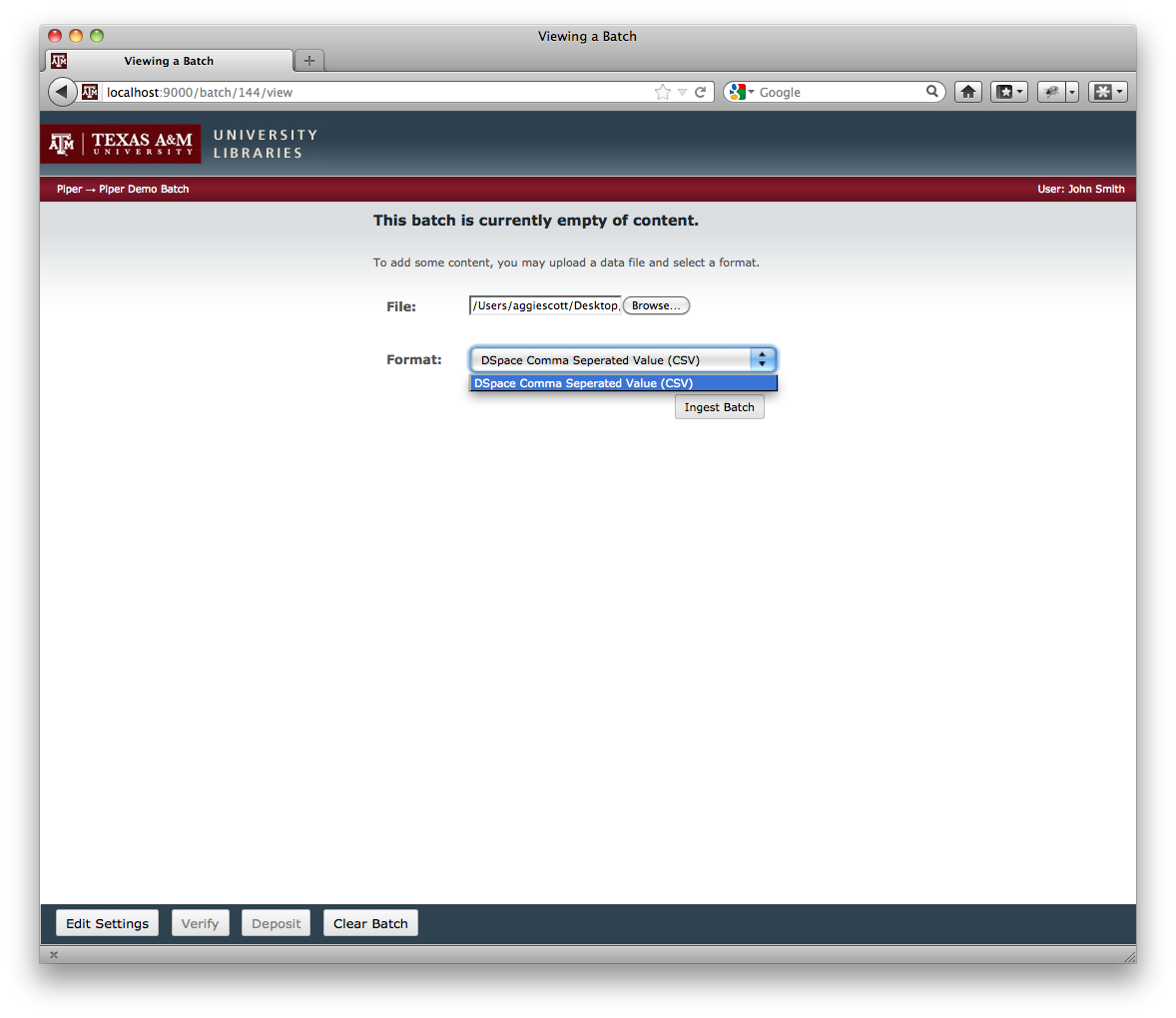
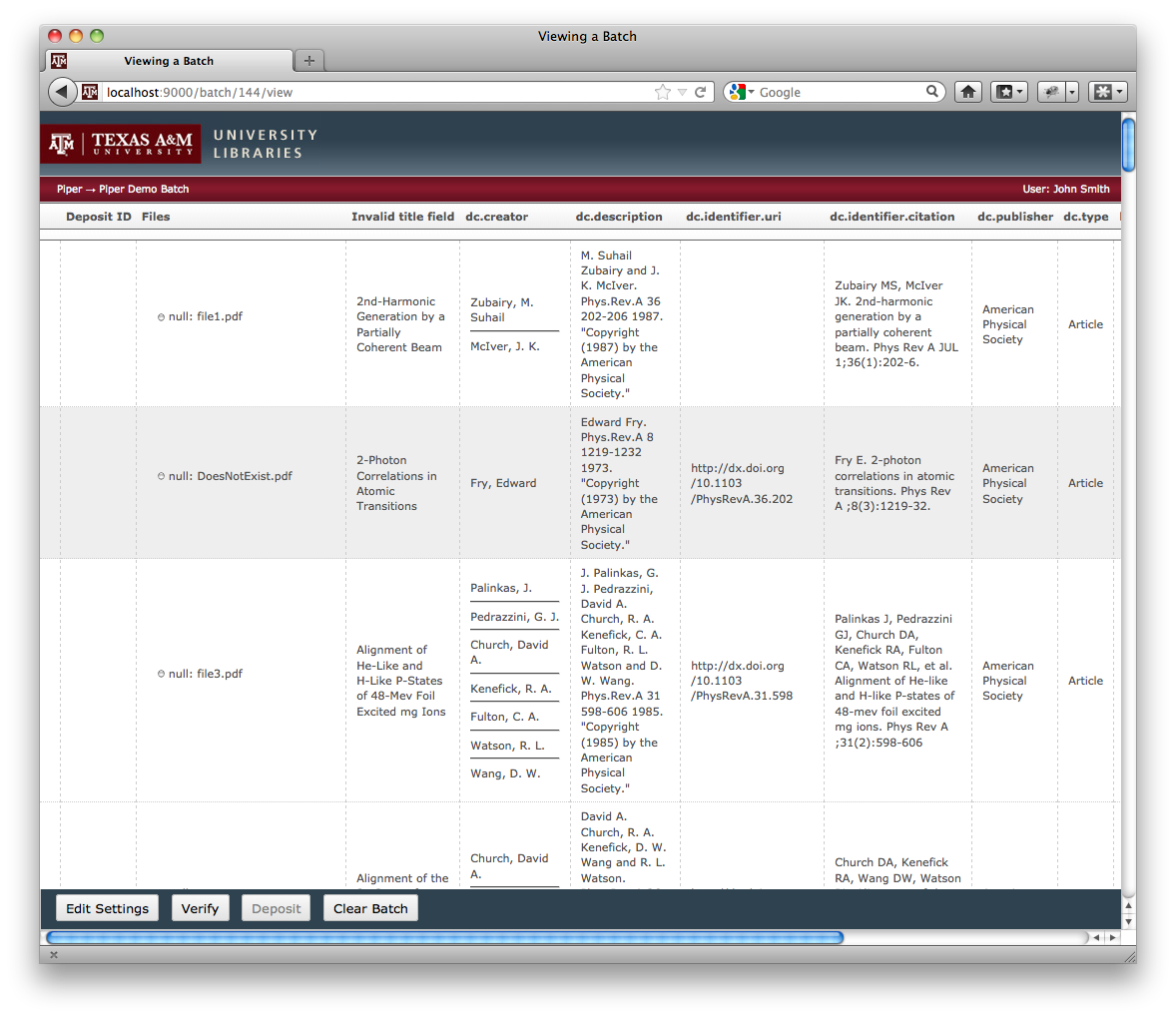
Once a batch has been ingested into Piper, it is ready to be verified. The current version is read-only, i.e. to make any changes you need to go back to your spreadsheet update it and re-upload it. However, the necessary UI adjustments to edit the content directly with-in Piper will likely be added in a future version. Each repository is pre-configured with a set of verifiers (each is a simple Spring bean for easy extensibility). Each verify will scan the batch and identify any errors - things that we know will not work, or warnings - things that might not work. Some things they check are whether the column label is valid Dublin Core, or whether 90% of the items contain a particular field but there is an item with that field missing. Right now there are seven different verifiers almost all of them are completely related to DSpace and Dublin Core. As other formats and repositories are supported the list of verifiers will expand.
Once a batch has been verified and contains no errors it is ready to be deposited. The librarian simply clicks the deposit button and each item is ingested into the repository one at a time via SWORD into the destination collection. Right now Piper only supports SWORD version 1, so it’s a one shot deal. With support for Sword 2 in a future version, it will allow us to deposit the batch into a repository and then some time later if we find an error re-deposit the item back into the repository updating the existing item in the repository without assigning it a new identifier.
Technical notes
The application is developed using the Play Framework using Java, Spring, JPA, etc. These collections of tools proved to be a very productive environment for Piper. One of the cool new HTML 5 technologies that we used in Piper is Web Sockets. Web sockets allow the browser to open a persistent TCP connection back to the server for two way communication. We use this extensively in Piper for the spreadsheet view. When the page loads initially the content is blank. The browser opens a web socket back to the web server where Piper starts feeding all the batch content over the web socket back to the browser for display. This allows us to display a page with 20k items on it and not deal with time out issues, or blocking issues. The page is constantly working in the background to display the items while the user is able to interact with their web browser. This approach also allows us to push updates to the users browser. This is important because some of the tasks are long running such as verifiers, ingesters, depositors, etc, may take several minutes to hours to complete. While these are running on the server the user’s browser is able to update the changes in real time without reloading the page. Very cool stuff.
What is next?
Piper is an internal project for Texas A&M University Libraries and has not gained approval for release as an open source project. I hope that we will be able to make it public so that others can check it out and see if it’s useful for them. Right now it only supports a very limited set of formats that need to be expanded. Most of our development focus for the rest of the year will be on Vireo, so it may be sometime before we jump back to further development on Piper.
Screenshots